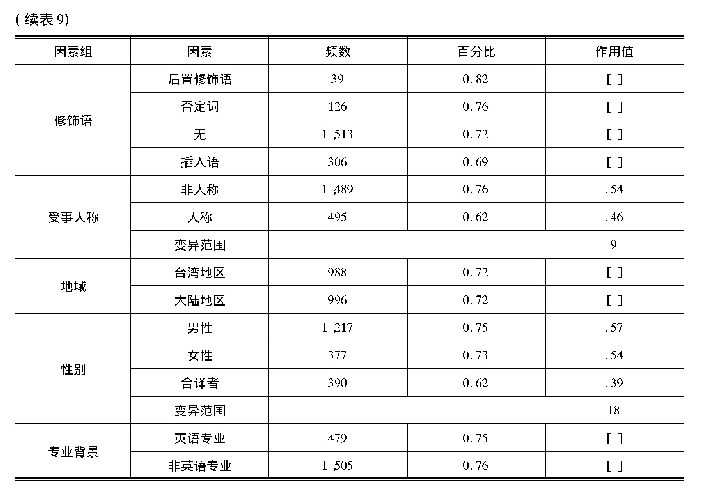
《表9 汉语译文主动结构变项规则分析结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《海峡两岸翻译文本“被”字句变异研究——变项规则分析法在描写译学中的应用》
本研究中汉语译文中所有用来表达英语被动结构关系的句式看出一个集合体,由此就可能做到穷尽性搜索,做封闭环境下的定量分析,以使我们的研究进一步走向精确化和精密化。VARBRUL已经实现了软件化,本研究采用了R语言环境下的Rbrul(Johnson,2009)。根据4.1的描述统计结果,隐性为汉语译文的重要特征。因此,我们把汉译主动结构作为因变量,然后对其进行“二项阶增/阶减分析”(binominal step-up/step-down analysis)。自变量包括语义、句法、语用等语言因素以及译者性别、地域、教育背景等社会因素。其中英语被动结构中的769个谓语动词为随机变量。在此基础上,建立混合效应(mixed effects model)模型。运行Rbrul多元回归分析,结果见表9所示。多变量分析结果显示,非被动式汉语译文的校正均值为0.58。译者在翻译英语被动结构时,依然首选非被动式,汉语译文的传统化和规范化特征明显。其次,影响非被动式汉语结构的因素组包括语义韵、受事人称性、施事隐现。对于性别而言,如果不考虑合译者,性别差异不显著,男性使用非被动式的频率略高。而其他句法功能、修饰语有无、地域、教育背景等因素组则不具有显著制约作用。
| 图表编号 | XD00212273400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.15 |
| 作者 | 郭鸿杰、宋丹 |
| 绘制单位 | 上海财经大学外国语学院、上海交通大学外国语学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}