《表5 象草eg7和eg87转录组数据unigene组装统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
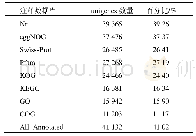
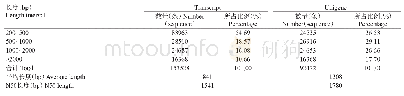
采用Illumina Hiseq 2000高通量测序技术对象草茎组织进行转录组测序,共得到了169630902条原始片段,过滤去除低质量片断和接头后获得153204888条、共13788439920nt的clean read,其Q20%为97.25%~98.48%(表3)。原始测序数据已提交到NCBI的序列片段归档(sequence read archive,SRA)数据库(BioprojectID:PRJNA357342)。经Trinity程序(http://trinityrnaseq.sourceforge.net/)对象草转录组clean read进行无参拼接后,共获得317216个contigs(eg7:148201;eg87:169015),其中≥500nt的contig序列有37155个(eg7:17259;eg87:19896)(表4) ,在contig数据基础上,进一步对序列进行组装,共获得87641个unigene序列,平均长度为580nt,N50为780nt,其中12863unigene(14.68%)序列长度大于1000nt(表5)。
| 图表编号 | XD0029525100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.20 |
| 作者 | 吴娟子、钱晨、刘智微、潘玉梅、钟小仙 |
| 绘制单位 | 江苏省农业科学院畜牧研究所、国家牧草育种创新基地、农业部种养结合重点实验室、江苏省农业科学院畜牧研究所、国家牧草育种创新基地、农业部种养结合重点实验室、江苏省农业科学院畜牧研究所、国家牧草育种创新基地、农业部种养结合重点实验室、江苏省农业科学院畜牧研究所、国家牧草育种创新基地、农业部种养结合重点实验室、江苏省农业科学院畜牧研究所、国家牧草育种创新基地、农业部种养结合重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}