《表5 数值模拟工况:基于分步迁移策略的苹果采摘机械臂轨迹规划方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
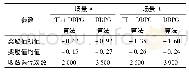
由图12和表5可以看出,与DDPG算法训练相比,在场景A和场景B中基于迁移学习的DDPG算法训练收敛所需迭代次数从3 500和3 900分别缩短到2 000和2 600,收敛速度分别提升了42.86%和33.33%。说明机械臂在无障碍场景下的轨迹规划策略能够为单一障碍场景的轨迹规划提供指导,可以有效缩短训练时间。
| 图表编号 | XD00204484300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 郑嫦娥、高坡、GAN Hao、田野、赵燕东 |
| 绘制单位 | 北京林业大学工学院、北京林业大学工学院、田纳西大学生物系统工程及土壤科学系、北京林业大学工学院、北京林业大学工学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}