《表4 共同支持域区间:高学历家庭影子教育支出是否更多——基于倾向值匹配的考察》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《高学历家庭影子教育支出是否更多——基于倾向值匹配的考察》
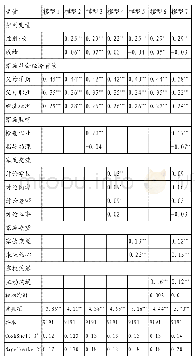
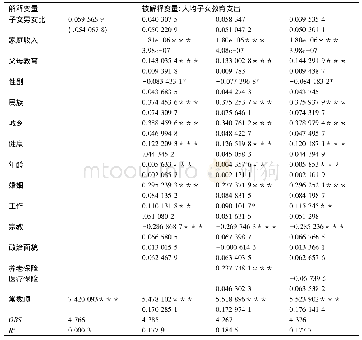
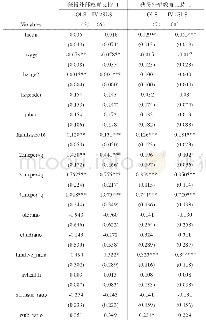
本文的所有匹配方式均是以表3的logit模型作为倾向值预测模型。倾向值匹配法要求控制组与处理组在倾向值的分布上具有较大的重叠性。从图1看,高等教育获得组与非高等教育获得组之间的“共同支持区间”(common support region)比较大,这意味着数据应用条件较好。再通过表4可以看出,在总共3 757个观测值中,控制组共有15个不在共同取值范围中(off support),处理组共有26个不在共同取值范围中(off support),其余3 716个观测值均在共同取值范围中(on support)。表5~6说明,不管使用哪种倾向值匹配方法,几乎都在各个变量上实现了高等教育获得组与非高等教育获得组之间的平衡(处理组与控制组的倾向平均得分较为接近,平衡性检验大部分通过[P值不显著]),只有极个别的变量继续呈现显著性。
| 图表编号 | XD002088900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.11.10 |
| 作者 | 王晓磊、张强 |
| 绘制单位 | 武汉大学社会学系、武汉大学妇女与性别研究中心 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}