《表5 Heckman两阶段模型检验》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
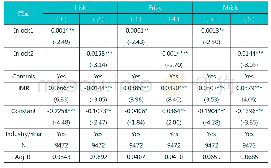
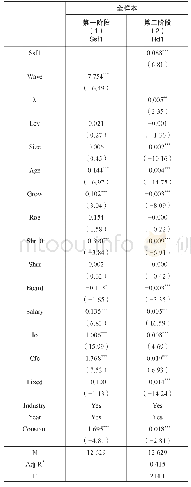
2.采用Heckman两阶段回归模型控制样本选择偏误问题。参考刘斌等(2019)的研究,在第一阶段的Probit模型中,在控制了公司规模、股权集中度、再融资、公司价值、上市年限、董事薪酬、董事会规模、产权性质等变量的基础上,本文设立以“连锁董事数量是否较多”以及“连锁董事比例是否较高”为因变量的定性回归模型。对于该因变量的定义,若连锁董事数量及连锁董事比例超过当期行业年度中位数,则取值为1,否则取值为0。之后,根据定性回归模型计算IMR(Inverse Mills Ratio),将其代入主回归模型进行第二阶段回归,检验结果如表5。结果显示,相比连锁董事数量较少和连锁董事比例较低的公司,连锁董事数量较多和连锁董事比例较高的公司信息风险、基本面信息风险和操控性信息风险显著较低。由此证明,在控制了连锁董事的选择性偏误后,连锁董事较多的公司信息风险、基本面信息风险和操控性信息风险均更低。
| 图表编号 | XD00188735500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.01 |
| 作者 | 蔡慧 |
| 绘制单位 | 盐城工学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}