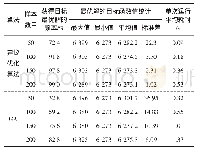
《表1 算法在F1~F6上独立运行20次的MER的平均值和标准差值比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
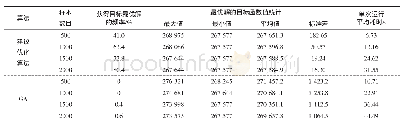
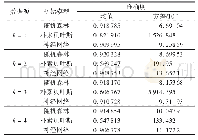
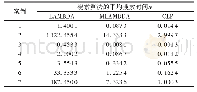
由表1和图2可以看出,在MER值方面,DDMOPSO算法与其他所有比较的算法都有着更好的收敛性.在t=40之前,各种算法的差异主要是因为在更新粒子群时将局部最优和全局最优考虑在内.因此,PSO比其他的交叉和变异算子具有更好的收敛性,同时,群预测策略能够找到有用的粒子来加速收敛.当40?t<160时,除了F4的MER值与dMOPSO持平外,DDMOPSO均优于其他算法.F4函数是一个比较困难的3目标问题,而从图2(d)中可以看出,这两种基于分解的算法性能相似.另外,在表2的F4函数上,DDMOPSO的MIGD值显然低于dMOPSO.
| 图表编号 | XD0054188700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 耿焕同、周山胜、陈哲、韩伟民 |
| 绘制单位 | 南京信息工程大学计算机与软件学院、南京信息工程大学计算机与软件学院、南京信息工程大学计算机与软件学院、南京信息工程大学计算机与软件学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}