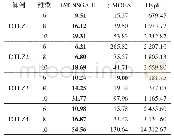
《表2 UCI数据集上不同算法的平均可聚类比率分布和运行耗时比较(算法各运行100次)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:每次递增的数据量Nadd={100,101,102,…,Nall},Nall为总数据量。3 UCIDBSCAN
从表2可以看出,Hopkins和T-平方在递增数据序列上的表现是100次运行的平均可聚类比率AR(可聚类比率指数据在递增过程中可聚类判断次数占总聚类趋势判断次数的比值)大于94%,SpecVAT则在87%以上,这都明显高于MDCG-CTI的平均显著可聚类比率,究其原因:一方面是因为误认为单簇分布是可聚类的,另一方面则是将含大量噪点的数据集判断为可聚类。所以相比之下,MDCG-CTI对聚类趋势的判断要更准确,从而其相对较低的可聚类比率在后续的批量增量DBSCAN中便可以更有效地减少无效聚类,降低聚类耗时,同时提高聚类结果的有效性。而从算法各运行100次的可聚类比率标准差ER上来看,Hopkins和T-平方基本上在0.01左右,SpecVAT在0.006左右,MDCG-CTI则约为0.003,可见MDCG-CTI算法的波动幅度最小,稳定性最高,而Hopkins和T-平方则因为抽样的关系导致结果相对片面和不稳定。
| 图表编号 | XD00197698100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.10 |
| 作者 | 樊仲欣 |
| 绘制单位 | 大气科学与环境气象国家级实验教学示范中心(南京信息工程大学) |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}