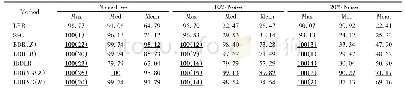
《表3 UCI数据集上不同算法结合DBSCAN的聚类结果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表3中在数据按照数据量Nadd随机递增的过程中,由于增加聚类趋势算法所减少的若干次不具有聚类趋势(不可聚类)的DBSCAN聚类,其结果大多是聚类成单簇或噪点过多而导致准确率不高,所以用了聚类趋势分析算法以后聚类的CR便会提高,而因MDCG-CTI的平均可聚类比率AR是最低的(见表2),所以其后续DBSCAN的聚类CR也就相应最高,相较SpecVAT+DBSCAN在数据集pendigits和avila上分别提高了6和11个百分点。此外聚类累计耗时T方面,iris数据集由于数据量小而聚类耗时很短,所以使用聚类趋势算法后耗时均比不使用要多,且以SpecVAT最为突出;但是在pendigits和avila两个大数据集上,聚类趋势算法减少DBSCAN聚类耗时的优点则显露了出来,其中Hopkins由于100%可聚类的关系(见表2)所以耗时比只用DBSCAN多,而其余三种聚类趋势算法结合DBSCAN后累计耗时T都有所减少,且MDCG-CTI减少得最为明显,相较SpecVAT+DBSCAN的聚类累计耗时分别降低了7%和8%。
| 图表编号 | XD00197697000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.10 |
| 作者 | 樊仲欣 |
| 绘制单位 | 大气科学与环境气象国家级实验教学示范中心(南京信息工程大学) |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}