《表2 K-means和ECKM在八个数据子集上的平均F1值和标准差(mean±SD)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
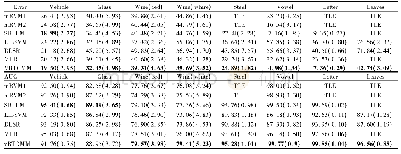
本节主要分析基聚类算法和聚类集成方法在学术文本类别划分中的性能差异,主要对各数据集的F1值和所有数据集的平均F1值进行比较。本文共采用八个数据集进行学术文本类别划分实验。表2表示K-means与ECKM聚类方法在基于CSI、ECC、TextRank和TFISF这四种关键词抽取方法在八个数据子集上的平均F1值,表3表示增量聚类(IC)与ECIC聚类方法在基于CSI、ECC、TextRank和TF‐ISF这四种关键词抽取方法在八个数据子集上的平均F1值和标准差。表2和表3中的灰色部分表示聚类集成方法的F1值高于基聚类器的F1值。从表2和表3可以看出,聚类集成方法的性能普遍高于基聚类器聚类器。在K-means与ECKM的比较中,当CSI和TFISF用于关键词抽取时,ECKM的F1值均高于K-means;当将ECC、TextRank作为关键词抽取方法时,部分K-means的F1值高于ECKM,但该部分的比例较小,分别占总结果的33%和42%。为了对K-means和ECKM的性能差异进行详细分析,本文使用T检验分析了两者的平均F1值,其结果(t=7.082,P=0.000)表明,两者的F1值存在显著性差异,且ECKM的性能显著高于K-means。在增量聚类与ECIC的比较中,在四种关键词抽取方法下部分增量聚类的F1值高于ECIC,但该部分较小分别占总结果的25%、25%、17%和33%。另外其T检验结果(t=3.524,P=0.000)表明两者的F1值存在显著性差异,且ECIC的性能显著高于增量聚类。这些观察表明聚类集成更适用于对学术文本类别进行自动划分。
| 图表编号 | XD0072260200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.24 |
| 作者 | 张颖怡、章成志、陈果 |
| 绘制单位 | 南京理工大学信息管理系、中国科学技术信息研究所、南京理工大学信息管理系、中国科学技术信息研究所、南京理工大学信息管理系 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}