《表1 学术文本数据集信息[7]》
![《表1 学术文本数据集信息[7]》](http://bookimg.mtoou.info/tubiao/gif/QBXB201908010_02600.gif) 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
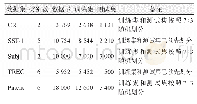
本文在数据集的选择上制定了以下要求:(1)准确的学术文本类别划分,以保证实验结果的准确性;(2)需包含多个测试数据子集,以提升实验结果可靠性;(3)各类别数据量较平均,以减轻数据集的类别不均衡问题。Rossi等[7]数据集满足以上要求。该数据集包含40个领域的3506篇论文,采集自ACM计算机学科分类体系(CCS2012)。该分类体系由120位ACM学科领域志愿者构建,将计算机学科划分为5个垂直层次的研究领域。由于该体系为人工构建,对学术文本划分的精确度较高,可作为聚类结果的判断标准。同时,该数据集包含8个测试数据子集(表1中的ACM-1~ACM-8),每个子集包含5个领域的论文数据。为提升实验结果的可靠性,文本类别划分实验分别在这8个子数据集上展开。另外,该数据集中各领域的论文数量较平均,减轻了数据集类别不均衡问题。在关键词的选择上,由于ACM数据库和学术文本作者赋予的关键词数量较少,易造成数据稀疏等问题。因此,本文选择使用关键词自动抽取方法,从文本中抽取关键词代表文本主旨内容。该数据集的详细信息如表1所示。
| 图表编号 | XD0072260100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.24 |
| 作者 | 张颖怡、章成志、陈果 |
| 绘制单位 | 南京理工大学信息管理系、中国科学技术信息研究所、南京理工大学信息管理系、中国科学技术信息研究所、南京理工大学信息管理系 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}