《表2 数据集统计信息:针对文本情感分类任务的textSE-ResNeXt集成模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《针对文本情感分类任务的textSE-ResNeXt集成模型》
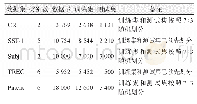
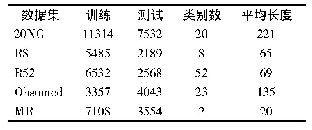
中文数据采用的是中国科学院计算技术研究所谭松波博士整理的一个较大规模的酒店评论语料,语料规模为10 000条,其中正向7 000条,负向3 000条。英文数据则采用标准英文数据集:MR[21]、SST[9]、Subj[21]。MR、SST、Subj为英文情感分类任务中的常见数据集。MR数据集语料规模为10 662条,其中正向和负向各有5 331条;SST数据集语料规模为6 840条,其中正向3582条,负向3 258条,训练集规模为2 667条,正向1 338条,负向1 329条;Subj数据集语料规模为10 000条,其中正向与负向各有5 000条,如表2所示。
| 图表编号 | XD00134393200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 康雁、李浩、梁文韬、宁浩宇、霍雯 |
| 绘制单位 | 云南大学软件学院、云南大学软件学院、云南大学软件学院、云南大学软件学院、云南大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}