《表1 数据集统计信息:面向短文本情感分类的端到端对抗变分贝叶斯方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
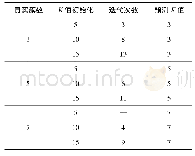
实验参考文献[10]的设置对原始数据进行预处理,并且所有的数据集按照80%、10%、10%的比例划分训练、验证和测试集。本文选用Han LP(Han Language Processing)作为分词工具,与文献[10]中使用搜狗语料库训练词向量模型不同的是,本文使用Li等[24]提供的预训练模型。考虑到本文的测试数据集多是来自于微博平台,因此选用在微博语料库上预训练的300维词向量模型。经过预处理后的数据集信息如表1所示,前两个数据集统一每条短文本词语数量为20,最后一个数据集设置词语数量为40。
| 图表编号 | XD00222672100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.10 |
| 作者 | 尹春勇、章荪 |
| 绘制单位 | 南京信息工程大学计算机与软件学院、南京信息工程大学计算机与软件学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}