《表1 数据集信息:基于DW-TCI的半监督文本分类方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
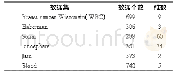
本文实验平台采用Windows 10 64位操作系统,CPU为Intel(R)Core(TM)i5-4210U,物理内存为12 GB,使用Python编程语言在pycharm2019平台上进行算法实现,机器学习框架为keras,分词工具为jieba[32]。使用两个数据集对模型的效果进行验证,数据一通过爬虫的方式由“汽车之家”网站获得,“汽车之家”对汽车的评论分为好评和差评,按评论种类爬取评论文本;数据二为搜狗新闻语料库中开源的数据集[33],为搜狐新闻2012年6月-7月期间国内、国际、体育、社会、娱乐等18个频道的新闻数据,受硬件计算能力限制,选择其中具有代表性的5类:汽车、财经、科技、体育、其他的部分新闻内容作为实验数据,数据集信息如表1所示。
| 图表编号 | XD00227029500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.25 |
| 作者 | 余本功、汲浩敏 |
| 绘制单位 | 合肥工业大学管理学院、合肥工业大学过程优化与智能决策教育部重点实验室、合肥工业大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}