《表1 数据集分布情况:基于语义与分类贡献的文本特征选择研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
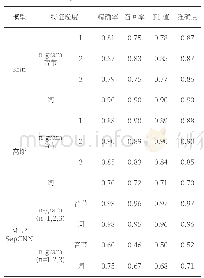
实验数据采用谭松波的中文文本语料集(Tan Crop Min),该数据包含10个类别共1901篇文本,其中训练集951篇,测试集950篇.其分布如表1所示.
| 图表编号 | XD00140120800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.15 |
| 作者 | 景永霞、苟和平、王治和 |
| 绘制单位 | 琼台师范学院信息科学技术学院、琼台师范学院信息科学技术学院、西北师范大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
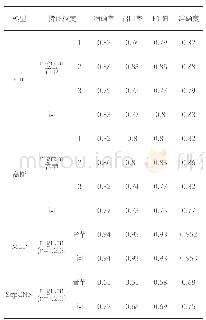
实验数据采用谭松波的中文文本语料集(Tan Crop Min),该数据包含10个类别共1901篇文本,其中训练集951篇,测试集950篇.其分布如表1所示.
| 图表编号 | XD00140120800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.15 |
| 作者 | 景永霞、苟和平、王治和 |
| 绘制单位 | 琼台师范学院信息科学技术学院、琼台师范学院信息科学技术学院、西北师范大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}