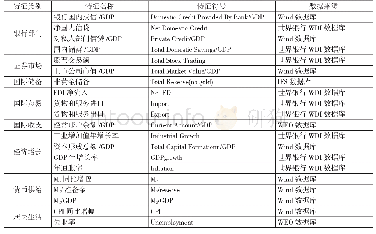
《表1 数据集概述:基于特征选择与随机森林混合模型的社区恶意评论检测研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于特征选择与随机森林混合模型的社区恶意评论检测研究》
本文通过Python爬虫,采集并清洗了来自社区chouti.com的公开数据,包含来自8,869名用户的3,450,059条历史发言记录。之后对采集到的原始数据进行了细致的检查和分析,发现原始数据中存在部分无效内容及数据重复等问题。因此本文对原始数据进行了清洗和预处理,以保证数据的准确性,最终获得46,036条被标记为“该评论已被删除”的数据。实验将未被删除的数据标记为0,被删除的数据标记为1,使用Sklearn实现PCA降维和随机森林算法。
| 图表编号 | XD00157057600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.05 |
| 作者 | 唐洵、汤娟、周安民 |
| 绘制单位 | 四川大学网络空间安全学院、四川大学网络空间安全学院、四川大学网络空间安全学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}