《表2 特征降维数据:基于KNN模型的藏文文本分类研究与实现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
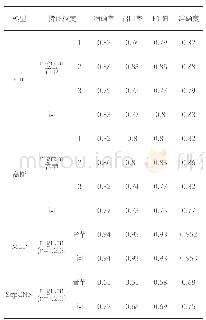
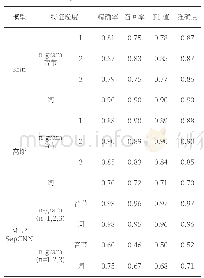
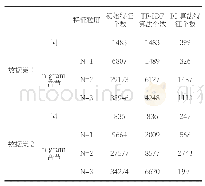
利用信息增益算法对实验语料样本进行特征降维降维处理结果如表2所示。由表2实验结果可知,通过词典匹配方法获得1,483个独立的样本特征,构成初始特征向量S1,然后利用信息增益算法较强的降维处理能力,对初始特征向量S1进行降维处理,最终形成维度为425的特征向量S2。降低藏文文本的词特征维度后,所获得的特征字符向量S2如图2所示。
| 图表编号 | XD0072180300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 苏慧婧、群诺、贾宏云 |
| 绘制单位 | 西藏大学信息科学技术学院、西藏大学信息科学技术学院、西藏大学信息科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}