《表1 本文数据集的描述:基于文本数据的过滤式与嵌入式样本选择算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
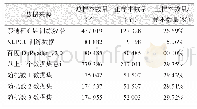
(4)设置三个随机数,在以上三个来源的数据集上分别随机选择5万个样本,为保证数据的连续性再选取每个样本的前一个样本和后两个样本,得到20万个样本,最后对选择出的样本去重,得到三个数据集,如表1所示。对每个数据集随机分割为训练集和测试集,比例为9∶1。
| 图表编号 | XD00139961400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.25 |
| 作者 | 刘书瑞、田继东、陈普春、赖立、宋国杰 |
| 绘制单位 | 西南石油大学理学院、西南石油大学理学院、西南石油大学理学院、西南石油大学理学院、西南石油大学理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}