《表1 实验数据集的分布:基于循环神经网络的图像特定文本抽取方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
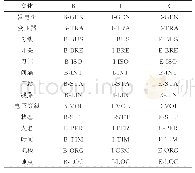
监督学习模型的训练要以大量带标签的训练集为基础,但由于缺乏标准的数据集训练本研究提出的模型,且人工标定数据耗时耗力,因此本文以身份证图像数据集作为研究对象,分析身份证的结构内容,设计算法,自动生成带标签数据,进行训练。部分生成数据如图7所示,其中共包含6种实体,name、gender、nation、birth、address、idnum,分别代表姓名、性别、民族、出生、地址、公民身份号码。本文要抽取的特定文本即为标注的6种实体,共生成训练集IDTRAIN 500份,验证集IDVAL 100份,如表1所示。
| 图表编号 | XD00119141300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.25 |
| 作者 | 杨恒杰、闫铮、邬宗玲、方定邦、段放 |
| 绘制单位 | 华侨大学信息科学与工程学院、华侨大学信息科学与工程学院、华侨大学信息科学与工程学院、华侨大学信息科学与工程学院、华侨大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
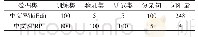




{kind=link}