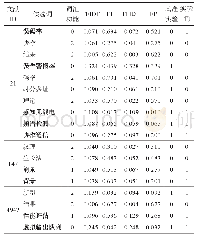
《表3 特定文本抽取完整性测试结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
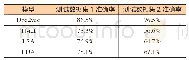
表3统计了数据集上所有样本中6种特定文本全部完整抽取的结果以及OCR部分与信息抽取部分的速度。可见,文本抽取部分无论是采用BLSTM-CRF模型还是CRF模型,其抽取速度远远大于OCR部分的识别速度,即利用本文方法与OCR结合进行信息抽取时,可以忽略由信息抽取部分带来的速度损失。整体耗时仍然是由OCR部分主导,体现本文模型具有更强的实时适用性。另外BLSTM-CRF模型虽然在抽取速度上略慢于CRF模型,但是其抽取信息的准确率高于CRF模型16.39个百分点,在有噪声文本的情况下仍能很好地将特定文本抽取出来,体现了模型的稳健性。采用CRF模型进行序列标注时,必须人工设置特征,实际效果受特征的限制,因此在泛化能力上,BLSTM-CRFs模型要优于CRF模型。
| 图表编号 | XD00119141500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.25 |
| 作者 | 杨恒杰、闫铮、邬宗玲、方定邦、段放 |
| 绘制单位 | 华侨大学信息科学与工程学院、华侨大学信息科学与工程学院、华侨大学信息科学与工程学院、华侨大学信息科学与工程学院、华侨大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}