《表7 分类抽取结果示例:学术文本词汇功能识别——在关键词自动抽取中的应用》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《学术文本词汇功能识别——在关键词自动抽取中的应用》
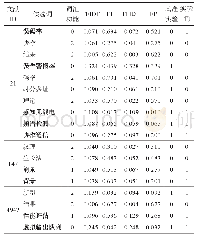
注:词汇功能“0”“1”“2”分别为“研究方法”“研究问题”“其他”,加粗的候选词为关键词,表中特征值均为归一化后的结果。
从表7数据可知,通过对“研究问题”和“研究方法”词进行加权后,其他候选词的加权特征(数据归一化后)相应地也会朝着相反方向有所改变,即词频特征变小,位置特征变大,使得上述两类关键词和其他词具有更大的距离,从而同时提高分类器对正例和负例的区分能力。但是,对于某些词频特征和位置特征较为反常的词,如文献4942中的“新型”一词,虽然不是关键词,但FI值很小,TFIDF值较大,加权特征也不明显,无论是基准实验还是实验(10)都难以判断正确,这说明本文提出的融合词汇功能的关键词自动抽取方法虽然有较好的效果,但对“其他”功能的候选词的识别仍需进一步改进。
| 图表编号 | XD00206682800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.24 |
| 作者 | 姜艺、黄永、夏义堃、李鹏程、陆伟 |
| 绘制单位 | 武汉大学信息管理学院、武汉大学信息检索与知识挖掘研究所、武汉大学信息管理学院、武汉大学信息检索与知识挖掘研究所、武汉大学信息资源研究中心、武汉大学信息管理学院、武汉大学信息检索与知识挖掘研究所、武汉大学信息管理学院、武汉大学信息检索与知识挖掘研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}