《表3 文本分类所抽取样本的数据分布》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
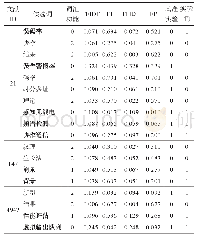
本研究对所爬取内容采用前文提出的文本预处理方法进行了主题内容预处理,包括:,(1)缺失值的处理,删除因信息缺失而无法利用的主题帖;(2)去除噪声,删除不需要的图片信息、附件、链接等内容的主题帖,剩余40 555条记录;(3)构建文本分类器进行文本分词和词性标注,因为本文所选取文本的特殊性,有大量小米产品、手机行业等的专业词汇,jieba分词自带的词典难以满足分词需求,所以增加用户自定义词典进行分词,并进行词性标注和停用词去除;(4)提取关键词并对文本分类器进行训练,随机选出2 000条样本主题帖来训练文本分类器,在训练文本分类器的过程中,根据前文对创新型和专业型主题帖的定义进行人工标记,然后采用7∶3的比例随机选取训练集和测试集。随机抽取样本的结果如表3所示。
| 图表编号 | XD003771400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 曾庆丰、郭倩、张岚岚、曹昶琦 |
| 绘制单位 | 上海财经大学信息管理与工程学院、上海财经大学信息管理与工程学院、上海财经大学信息管理与工程学院、上海财经大学信息管理与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
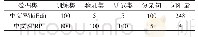

{kind=link}