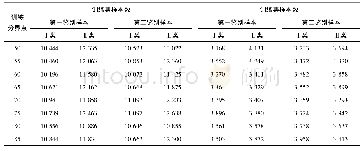
《表1 数据集样本分布表:基于LSTM的《红楼梦》文本风格分界点识别方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文生成的实验数据集如表1所示。其中Ⅰ类代表样本位于训练分界点之前,Ⅱ类样本位于训练分界点之后。从表1中可以看出,不同分界点的数据总数相似且数据平衡,这样可以有效降低其它因素对模型性能的影响,从而保证了分界点识别的准确性和可靠性。
| 图表编号 | XD00192246000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 朱东旭、严广乐 |
| 绘制单位 | 上海理工大学系统科学系、上海理工大学系统科学系 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}