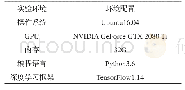
《表1 实验数据样本集:基于多重孪生网络的表面缺陷识别方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
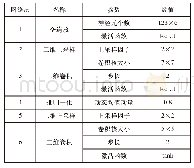
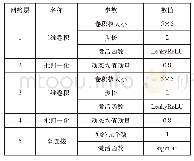
本文实验环境如表1所示;为测试算法所建立的标签缺陷数据集如图5所示。该数据集包括了汉字(简体、繁体)、数字、英文、日文、条形码及二维码等,几乎包含了国内所使用的打印标签的典型内容。数据集原始图片大小随机,在训练和测试时归一化到224×224尺寸。数据集中用于训练的样本数量为10 928张,其中正样本3 498张,负样本7 430张。负样本共分为4类,具体数量如表2所示。在测试时,参考标签与待测标签的类型可以完全不同,如待测图像为中文类型商品标签,对应参考图像可以是无缺陷的条形码标签、有打印墨点缺陷的英文标签或有污渍缺陷的日文标签等。
| 图表编号 | XD00197815100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.31 |
| 作者 | 王韵涛、盛庆华、郭晨洁、李竹 |
| 绘制单位 | 杭州电子科技大学电子信息学院、杭州电子科技大学电子信息学院、杭州电子科技大学电子信息学院、杭州电子科技大学电子信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}