《表1 实验数据统计:基于混合注意力机制的中文文本蕴含识别方法》
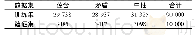 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
模型的训练语料来自CCL2018中文文本蕴含识别测评任务,该数据集包含9万个中文句子对,验证集包含1万个句子对,具体数据统计如表1所示。
| 图表编号 | XD00145322600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 黄生斌、肖诗斌、都云程、施水才 |
| 绘制单位 | 北京信息科技大学计算机学院、北京信息科技大学计算机学院、拓尔思信息技术股份有限公司、北京信息科技大学计算机学院、拓尔思信息技术股份有限公司、北京信息科技大学计算机学院、拓尔思信息技术股份有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}