《表2 分词结果:NLP在中医医案症状信息自动化抽取中的应用研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
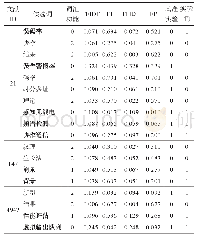
分词操作是医案信息抽取的基础,本研究采用的是Python的jieba分词。jieba分词是一种应用较为广泛的概率语言模型分词工具,其主要任务是在切分得到的所有结果中求某个切分方案S,使得P(S)最大。由于本研究是对特定领域进行分词,jieba的基础库中并没有医学领域专有词汇,因此需要创建自定义词典。创建本研究所需的心系医案数据词典流程描述如下:(1)读取100条心系医案数据,jieba分词并进行去停用词操作;(2)构建词典:遍历分词结果,构建“字词—频数”词典,按词频降序排列:{‘word’:freq},之后遍历词典,保留词数>1的词语并进行一定的人工干预,构建自定义词典;(3)读取100条医案数据,依据自定义词典进行jieba分词;(4)保留分词结果中词频>1的词语,与自定义词典进行比较,加入未登录新词,更新词典;(5)重复步骤(3)、(4),直到全部医案数据读取完毕。最终分词结果如表2所示。
| 图表编号 | XD00207311100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.15 |
| 作者 | 屈丹丹、杨涛、胡孔法 |
| 绘制单位 | 南京中医药大学人工智能与信息技术学院、南京中医药大学人工智能与信息技术学院、南京中医药大学人工智能与信息技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}