《表6 实验数据表:中文分词模型在中医病症语义理解中的研究与应用》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
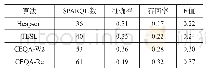
本文实验是通过Python实现了最大正向匹配分词算法,数据集是用txt格式来存储,通过Python程序读取。以20例病例作为测试病例,80例病例作为样本病例,经过多次调试最大分词数,分别计算他们的准确率和召回率,得出结果。结果对比发现组大分词数为5时,准确率和召回率最高,实验结果如表6所示。
| 图表编号 | XD00142811800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.05 |
| 作者 | 许林涛、叶欣欣、裴成飞、吴荣士 |
| 绘制单位 | 安徽理工大学、安徽理工大学、安徽理工大学、安徽理工大学 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}