《表1 实验数据分布:局部语义与上下文关系的中文短文本分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
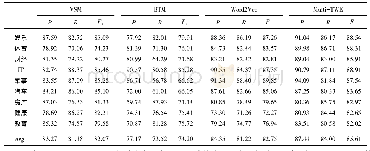
实验数据采用的是2017自然语言处理与中文计算评测(NLP&CC2017)公开评测数据,该数据包含18个类别的新闻标题文本,一条文本的长度平均约为22个字、13个词。训练集、测试集和验证集数量如表1所示。
| 图表编号 | XD00201612700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.15 |
| 作者 | 黄金杰、蔺江全、何勇军、何瑾洁、王雅君 |
| 绘制单位 | 哈尔滨理工大学自动化学院、哈尔滨理工大学自动化学院、哈尔滨理工大学计算机学院、哈尔滨理工大学自动化学院、哈尔滨理工大学自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}