《表3 水样水质化验结果:基于深度学习的中文网络招聘文本中的技能词抽取方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于深度学习的中文网络招聘文本中的技能词抽取方法》
由于没有明确的标准如何将数据集划分为训练/验证/测试集,在实验中将数据集进行两轮交叉验证。首先将整个数据集划分成5份,选择其中的80%作为训练数据,而将其余20%用作测试数据。然后,再次将训练数据划分成10份,选择其中的90%作为最终训练数据,并将其余的10%用作验证数据。换句话说,将全部数据的72%作为训练数据,将8%作为验证数据,将20%作为测试数据。每次实验的训练周期为100个周期,通过验证集找出训练集在这100个周期内最佳网络模型参数后再使用测试集进行测试,以获得本次验证的结果。表3中分别展示了用于训练、验证和测试数据集的句子数、技能词数量。值得注意的是,由于每个句子中包含的技能词数量不同,训练/验证/测试数据集中的技能词数量会随着每次划分而动态变化,因此,技能词数量的范围也在表中。
| 图表编号 | XD00190346800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.25 |
| 作者 | 文益民、杨鹏、文博奚、蔡翔 |
| 绘制单位 | 桂林电子科技大学广西可信软件重点实验室、桂林电子科技大学广西图像图形智能处理重点实验室、桂林电子科技大学广西可信软件重点实验室、桂林电子科技大学商学院、桂林电子科技大学商学院 |
| 更多格式 | 高清、无水印(增值服务) |
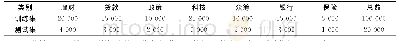

{kind=link}