《表3 基于深度学习的端到端的自然场景文本识别方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
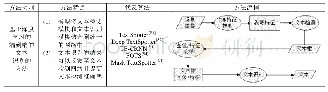
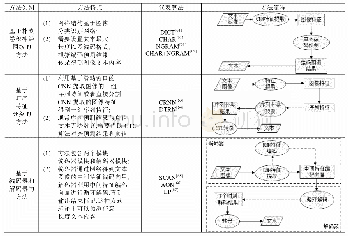
目前,大部分研究者将自然场景文本检测和识别分割为两个独立的任务,即首先利用检测网络得到图像中文本框,再将根据文本框得到剪裁的文本实例图像输入到文本识别网络识别文本内容.文献[80]尝试将文本检测和识别结合起来,利用基于滑动窗口的文本检测和字符识别模型构建一个端到端的文本识别系统,但本质上该系统依然将文本检测和识别分割为两个单独的模型,其中,滑动窗口的方法需要进行大量的计算,且复杂的后处理在实际应用效率并不高.与此不同的是,基于深度学习的端到端的自然场景文本识别方法将文本检测任务和文本识别任务结合在统一的网络模型中.该类方法通常共享底层卷积特征,根据共享特征检测文本区域,再将文本区域共享特征馈送到识别模块中识别文本内容.相较于将文本检测和识别分割为不同任务的方法,端到端的识别方法更具有挑战性,其优点在于,共享底层特征的方式降低了文本检测到识别过程的运算参数,并且其文本识别损失根据反向传播算法能够优化底层特征的提取和文本检测.本节将对端到端的自然场景文本识别方法(见表3)的特点、关键技术和主要优缺点进行分析介绍.
| 图表编号 | XD00168931700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 王建新、王子亚、田萱 |
| 绘制单位 | 北京林业大学信息学院、国家林业草原林业智能信息处理工程技术研究中心(北京林业大学)、北京林业大学信息学院、国家林业草原林业智能信息处理工程技术研究中心(北京林业大学)、北京林业大学信息学院、国家林业草原林业智能信息处理工程技术研究中心(北京林业大学) |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}