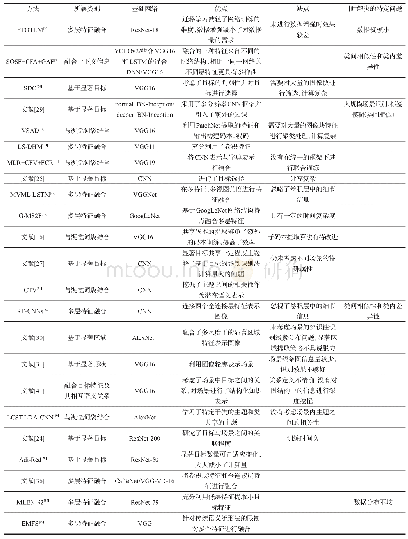
《表1 典型基于深度学习的场景识别方法比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
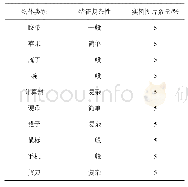
MIT Indoor67、SUN397、Scene 15数据集是场景识别任务中最常用的数据集。由表2可以发现,在对网络进行预训练时,除了用到以目标为中心的大型数据集ImageNet外,大多数方法都在大型场景数据集Places或其子集上对网络进行了训练,这一步有利于卷积神经网络能针对场景图像学习到更多丰富的特征。另外,通过表格可以看出,识别率较高的几个方法中都采用了数据增强操作,特别是文献[37]中效果提升最明显,进行数据增强一方面解决了数据量少的问题,一方面也有效防止了过拟合。从识别准确率来看,除了利用目标特征作为全局特征的补充特征外,结合有效的知识表示(例如文献[40]中的图像上下文特征)能有效帮助理解图像、提高场景识别率。利用显著性测量方法对场景中存在的目标进行选择,目标判别力越强越能代表一类场景,越能有效区分不同的场景类别,如文献[26],达到了相对较高的识别率;在文献[29]中,显著目标选择作为多分辨率网络结构的补充,一定程度上解决了标签模糊的问题,也帮助提升了识别效果;另外,文献[41]在构建场景子图时也对目标进行了选择。利用目标集中的显著区域或场景轮廓线条信息作为场景辨别性线索来进行场景识别效果并不理想。从文献[25,33,35]不同数据集上的实验结果来看,在SUN397(混合场景)上能达到相对较高精度的方法在MIT67(室内场景)上的效果却不突出,说明识别效果与数据集有关。
| 图表编号 | XD00134369800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 李新叶、朱婧、麻丽娜 |
| 绘制单位 | 华北电力大学电子与通信工程系、华北电力大学电子与通信工程系、华北电力大学科技学院 |
| 更多格式 | 高清、无水印(增值服务) |

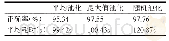

{kind=link}