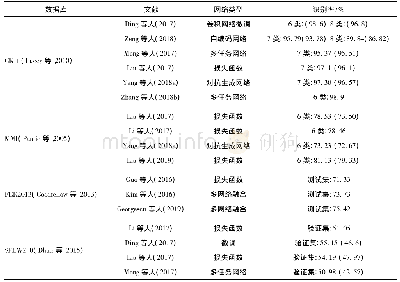
《表1 训练参数:端到端的低质人脸图像表情识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文实验通过在具有GPU的1080ti显卡的电脑上搭建TensorFlow框架来构建模型并训练,在训练本文模型之前首先利用CelebA人脸数据集上对生成模型进行预训练,然后使用本文处理后的Fer2013训练集和CK+数据集进行整个模型的训练,此时只需要微调生成模型部分,使用处理后的Fer2013测试集通过分类指标精度(Acc)和混淆矩阵[20]以对模型进行评估,最后在处理后的Fer2013测试集上对本文损失进行的分析.各个模型的训练参数如表1所示,设置α=0.85,β=0.1,γ=0.15通过实验发现本文对抗网络部分的对抗损失在0.05左右,而单独使用分类器的分类损失在0.3左右,比例为1∶6,为了平衡损失按比例设置超参数.而本文网络为了使网络侧重于分类,适当的调大分类损失部分的权重.本文的超参数并不一定是最优的.使用大于0小于1的数值是为了让初始损失不至于很大,随着梯度下降有一个平滑的损失曲线.
| 图表编号 | XD00141253500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 刘全明、辛阳阳 |
| 绘制单位 | 山西大学计算机与信息技术学院、山西大学计算机与信息技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}