《表2 专利文本特征抽取模型的测试结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
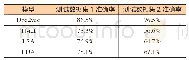
注:测试数据1为4000组全领域三元组准确率;测试数据集2为2000组手工代码T01下三元组准确率
表2为本文训练的Doc2vec专利文本抽取模型与经典的文本特征抽取模型的测试结果,从测试结果中可以看出本文训练的Doc2vec模型在专利特征抽取上远高于传统的词袋模型Tf-idf、主题模型LSA、LDA。在测试数据集1(4000组全领域三元组)中Doc2vec模型的准确率达到了86.5%,超过最好的LDA主题模型8.4%。在难度更高的测试数据集2(2000组手工代码T01下三元组)中,所有模型的准确率都有所下降,但Doc2vec的准确率依然达到76.5%,是所有模型中最高的。
| 图表编号 | XD00194062900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.16 |
| 作者 | 陈挺、邓启平、李国鹏、王小梅 |
| 绘制单位 | 中国科学院文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系、中国科学院科技战略咨询研究院、电子科技大学图书馆、中国科学院科技战略咨询研究院、中国科学院科技战略咨询研究院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}