《表1 实验数据分布:基于多尺度融合CNN的恶意软件行为描述语句抽取模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于多尺度融合CNN的恶意软件行为描述语句抽取模型》
本文所使用来自Phandi等人构建的数据集MalwareTextDBv2.0[12],Lim等人首先选择了39篇恶意软件报告[13],对其中描述恶意软件行为语句进行标注。Phandi等人在此基础上,将标注报告数量扩充到85篇。实验数据分布如表1所示,训练集包含65篇文档,共9424条语句,其中2204条语句是描述恶意软件行为或者能力。
| 图表编号 | XD0043317200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 陈文强、周安民、刘亮 |
| 绘制单位 | 四川大学网络空间安全学院、四川大学网络空间安全学院、四川大学网络空间安全学院 |
| 更多格式 | 高清、无水印(增值服务) |





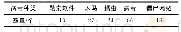
{kind=link}