《表1 数据集的统计:基于Transformer模型的中文文本自动校对研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Transformer模型的中文文本自动校对研究》
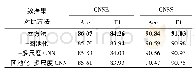
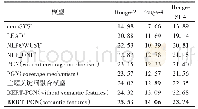
针对上述模型,本文设计了以下的实验。本实验运行环境操作系统为Windows 10,CPU为Intel誖Core TM i5-8265,GPU为GTX 1070Ti,运行内存8 GB。一共进行4组实验,分别为传统的Seq2Seq、加入BiLSTM的Seq2Seq、基于注意力机制的BiLSTM Seq2Seq与Transformer共4种模型。实验使用的数据集来自于2018 NLPCC共享的训练数据集Task 2,其中提供了717 206条中文文本语句对,将其中的700 000条作训练集,17 206条作测试集,划分过程随机。Src代表待校对语料,Trg表示原句所对应的正确语料。数据集的统计数据如表1所示,分为训练集和测试集,统计了正确语料和错误语料,以及分词后的词语总数。
| 图表编号 | XD00116442100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.06 |
| 作者 | 龚永罡、裴晨晨、廉小亲、王嘉欣 |
| 绘制单位 | 北京工商大学计算机与信息工程学院食品安全大数据技术北京市重点实验室、北京工商大学计算机与信息工程学院食品安全大数据技术北京市重点实验室、北京工商大学计算机与信息工程学院食品安全大数据技术北京市重点实验室、北京工商大学计算机与信息工程学院食品安全大数据技术北京市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
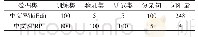



{kind=link}