《表1 数据描述性统计:基于语言模型的中文命名实体识别研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
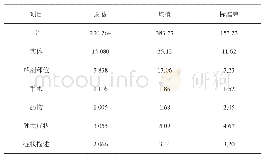
在MSRA数据集上对命名实体识别进行实验验证,并将模型应用到中文医疗文本(CCKS2020中文医疗文本命名实体识别数据集)上,数据集统计见表1。其中MSRA数据集包含3种命名实体:人名(PER)、地名(LOC)和组织(ORG);中文医疗文本包含6种实体:疾病和诊断、影像检查、实验室检验、手术、药物和解剖部位。
| 图表编号 | XD00218593900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.25 |
| 作者 | 张欣欣、刘小明、刘研 |
| 绘制单位 | 中原工学院计算机学院、中原工学院计算机学院、中原工学院计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}