《表1 数据集:基于迁移学习和BiLSTM-CRF的中文命名实体识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于迁移学习和BiLSTM-CRF的中文命名实体识别》
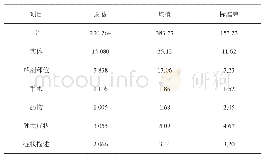
本文使用1998年1月份《人民日报》数据集进行中文机构名命名实体识别,该数据集是由北京大学计算语言学研究所和富士通研究开发中心有限公司共同制作的标注语料库.实验过程中,随机将其分为目标数据集、辅助数据集、测试数据集三部分,其中测试数据集占总数据集的10%,Dt是含有机构名命名实体标签和其他词性标签的目标数据集,Ds是把所有实体标签改为NN类型的辅助数据集.数据集分布情况如表1所示.
| 图表编号 | XD0079864500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 武惠、吕立、于碧辉 |
| 绘制单位 | 中国科学院大学、中国科学院沈阳计算技术研究所、中国科学院沈阳计算技术研究所、中国科学院沈阳计算技术研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}