《表1 数据集:Trans-NER:一种迁移学习支持下的中文命名实体识别模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《Trans-NER:一种迁移学习支持下的中文命名实体识别模型》
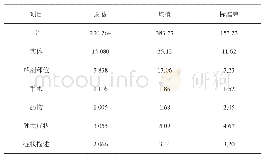
本文采用的基础字向量为100维字向量.采用的实验数据为中国法律文书网1上的大量公开法律文书,利用这些文档构建语言预测模型训练集与NER数据集.数据集的统计信息如表1所示.NER数据集使用IOB标注模式(Inside,Outside,Beginning)进行标注,其中包括3种实体类型,人名、地名和组织名(PER,LOC,ORG),共7种标签('O','B-ORG','I-ORG','B-PER','I-PER','B-LOC','I-LOC').
| 图表编号 | XD0079885200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 王银瑞、彭敦陆、陈章、刘丛 |
| 绘制单位 | 上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}