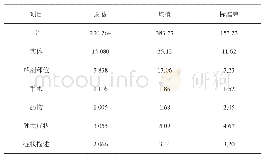
《表1 实验数据集规模:基于膨胀卷积的中文命名实体识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
中文命名实体识别是典型的序列标注问题,通过每个字符的不同标签,区分不同的实体。本文使用BIOES标注法,B、I、E分别表示实体的开始、中间和结尾,O表示非实体字符,S表示单字实体。本次实验使用了两个数据集,分别是MSRA数据集[18]和财经简历(resume)数据集[19]。MSRA是微软亚洲研究院提供的中文数据集,主要是新闻领域相关文本,是命名实体识别任务经典数据集。简历数据集来自新浪财经,数据内容主要是中国金融从业者的简历。数据集大小如表1所示。
| 图表编号 | XD00219108300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 张东、迟呈英、战学刚 |
| 绘制单位 | 辽宁科技大学计算机与软件工程学院、辽宁科技大学计算机与软件工程学院、辽宁科技大学计算机与软件工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}