《表4 语料库规模:基于句子级Lattice-长短记忆神经网络的中文电子病历命名实体识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于句子级Lattice-长短记忆神经网络的中文电子病历命名实体识别》
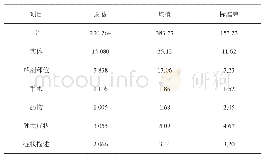
本研究使用向量训练工具Word2vec基于大规模医学专业文本训练了2个字符向量集,准备了2个训练语料库,第1个是电子版的内科学、外科学、妇产科学和儿科学4本医学专业书(以下简称nwfe_emd),第2个语料是2017年CCKS竞赛发布的未标注EMR数据(以下简称unlabel_emd)。用Python进行数据清洗,去掉与专业内容无关的部分,然后进行字符粒度分割,分割后作为模型输入在Word2vec中进行预训练分别得到nwfe_emd和unlabel_emd 2个字符向量集。字符分割后训练的向量集规模如表4所示。
| 图表编号 | XD0055525300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.20 |
| 作者 | 潘璀然、王青华、汤步洲、姜磊、黄勋、王理 |
| 绘制单位 | 南通大学医学院医学信息学教研室、南通大学医学院医学信息学教研室、哈尔滨工业大学(深圳)计算机科学与技术学院、海军军医大学(第二军医大学)长征医院风湿免疫科、南通大学信息科学技术学院通讯工程教研室、南通大学医学院医学信息学教研室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}