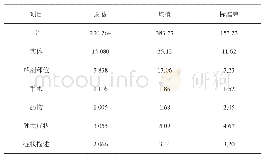
《表5 模型对比:基于多注意力的中文命名实体识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由表5中数据可以看出,使用本方案进行中文命名实体识别在精准度上高于使用双向长短期神经网络[9]和条件随机场这一传统模型,说明使用Transformer编码器提取的文本特征优于LSTM提取的文本特征,能够更好地表达文本字符之间的内在联系,通过多注意力可实现类似Convolutional Neural Network里的卷积操作,从多维度提取特征[10],每个编码器均使用不同的线性变换表达文本信息,从而更全面的表达文本的信息。在处理边界模糊的字符时,可根据当前字符的注意系数判断和该字符有着密切联系的其他字符,从而很好地区分一些边界模糊的实体,如“今日头条品牌运营公司—北京字节跳动科技有限公司”这一文本,在识别今日头条产品实体时,通过注意力可分析出“品牌运营公司”的更多注意力放在了后面的语句,和产品名称的联系较低。同时可看出该方法的召回率和综合性能F1值相比传统模型的提升不是很明显。
| 图表编号 | XD0079752900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.15 |
| 作者 | 顾凌云 |
| 绘制单位 | 上海冰鉴信息科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}