《表2 实体数量统计:基于深度学习和多特征融合的中文电子病历实体识别研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于深度学习和多特征融合的中文电子病历实体识别研究》
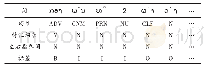
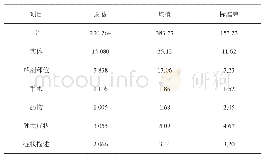
由于目前没有公开的大规模中文电子病历标注数据集,因此本研究组通过学习、培训和统一标注规范等大量准备工作标注了一定规模的中文电子病历语料.在已有研究基础上将医疗实体分为疾病(Disease)、症状(Symptom)、组织器官(Organ)、检查(Check)和治疗(Treatment)五类.标注各类实体时以首字母代替,并用BIESO方式标注.其中B,I,E分别表示实体开始、中间和结束,O表示非实体,S表示为单独实体.为减小中文分词对医疗实体识别的影响,标注医疗实体时用基于字的标注方式,这也是目前实体识别研究中常用的做法[5,9].研究小组标注了310篇中文电子病历,共28万多字,各类实体数量如表2.这些病历来自江苏某医院风湿科,实验时将所有病历随机打乱,按9∶1划分为训练集和测试集,进行十折交叉验证,取十次结果的平均值作为最终结果.此外,还有从好问康、求医问药网获取的论坛问答数据用于训练词向量,包含帖子36745个,共105 MB.
| 图表编号 | XD00109595100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.30 |
| 作者 | 韩普、刘亦卓、李晓艳 |
| 绘制单位 | 南京邮电大学管理学院、江苏省数据工程与知识服务重点实验室南京大学、南京大学信息管理学院、南京医科大学基础医学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}