《表2 不同数据集的结果,%》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
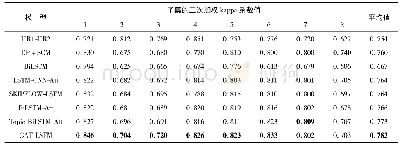
分别在MSRA和简历数据集上实验,结果如表2所示。总体来说,使用条件随机场模型的F1评分均有提升。Bi-LSTM-CRF模型比Bi-LSTM模型在MSRA数据集上提高了9.53%,在简历数据集上提高了2.07%。相比于Bi-LSTM模型,GDCNN-CRF模型在MSRA和简历数据集F1值分别提高了10.31%和4.87%。由于条件随机场可以从数据分布中学习到相邻标签之间的潜在关系,所以使用条件随机场的模型在F1值上会显著提高。在同样使用条件随机场的条件下,在MSRA数据集上GDCNN-CRF模型F1值相比于BiLSTM-CRF模型提高了0.78%,在简历数据集上提高了2.8%。同时,在简历数据集上,GDCNN-CRF模型的精确率相比于Bi-LSTM-CRF模型提高了3.76%。加入了Glo Ve词向量的膨胀卷积模型可以更准确地识别出实体。
| 图表编号 | XD00219108400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 张东、迟呈英、战学刚 |
| 绘制单位 | 辽宁科技大学计算机与软件工程学院、辽宁科技大学计算机与软件工程学院、辽宁科技大学计算机与软件工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}