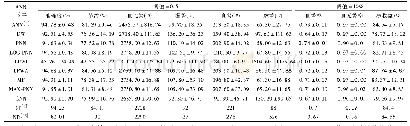
《表2 WIKIQA数据集上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《MGSC:一种多粒度语义交叉的短文本语义匹配模型》
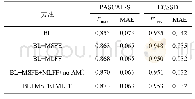
针对MGSC模型的四种变形,我们在WIKIQA数据集上进行了实验.这四种变形是通过在同等实验条件下,改变语义交叉特征图的数量和种类而得到的.在图4中,MGSC@1模型只用到两个句子原语义的交叉,包括一张交叉特征图;MG-SC@3模型用到两个句子的原语义与原语义、正语义和正语义、反语义和反语义交互形成的三张交叉特征图;MGSC@4模型是两个句子的原语义和正语义两两交互,形成四张语义交叉特征图,不加入反语义;MGSC@9模型,即我们提出的M GSC模型,采用两个句子的原语义、正语义、反语义之间两两交互形成的九张语义交叉特征图.该图表明,语义交叉是一种行之有效的语义匹配方法.比较MGSC@1模型和MGSC@4模型,可以看到模型中加入正向语义带来明显的效果提升;比较MGSC@1和MGSC@3两个模型,同样能说明加入正向语义和反向语义的优势;比较MGSC@1模型和MGSC@4、M GSC@9三个模型,实验结果表明,不同粒度的语义交叉能够带来效果的有效提升.
| 图表编号 | XD0079864600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 吴少洪、彭敦陆、苑威威、陈章、刘丛 |
| 绘制单位 | 上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院、上海理工大学光电信息与计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}