《表1 文本数据集的属性:维语网页中n-gram模型结合类不平衡SVM的不良文本过滤方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《维语网页中n-gram模型结合类不平衡SVM的不良文本过滤方法》
为了测试网页文本中的各种不良主题,从各种维吾尔文网站论坛上收集了500篇文本,分为四类:a)毒品类的文本,数量为143篇;b)色情类的文本,数量为78篇;c)赌博类的文本,数量为107篇;d)正常文本,数量为172篇。这些文本及其类别具有不平衡性,文本集的字符长度统计如表1所示。
| 图表编号 | XD00107261200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 如先姑力·阿布都热西提、亚森·艾则孜、郭文强 |
| 绘制单位 | 新疆警察学院信息安全工程系、新疆警察学院信息安全工程系、新疆财经大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
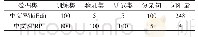





{kind=link}