《表4 分类器成对统计分析的分数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《维语网页中n-gram模型结合类不平衡SVM的不良文本过滤方法》
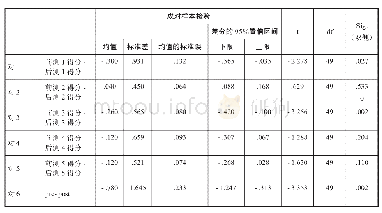
测试的错误率以及整体错误率的统计分析结果如表4所示。由于数据集具有不平衡性,有些类别的样本数量较少。从统计结果可以看出,所有测试均拒绝少数类别的假设。对于多数类别来说,假设在两个数据集上被拒绝并在其他三个数据集上被接受,则意味着两个数据集中的错误率在其他分类器上存在差异,但在其他三个数据集上没有差异。至于整体错误率,所有数据都接受假设,这意味着整体错误率没有差异。总之,本文CUB-SVM分类器在少数类别上具有较好的准确性,同时不会牺牲整体的准确性,这说明了本文分类器能够很好地处理不平衡数据。
| 图表编号 | XD00107261100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 如先姑力·阿布都热西提、亚森·艾则孜、郭文强 |
| 绘制单位 | 新疆警察学院信息安全工程系、新疆警察学院信息安全工程系、新疆财经大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}