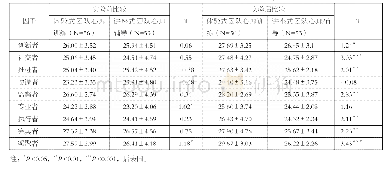
《表4 T次 (T=10) 增量学习后实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于选择性抽样的SVM增量学习算法的泛化性能研究》
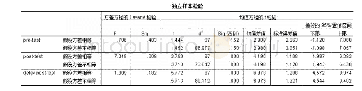
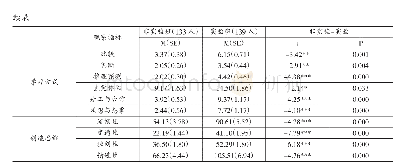
从表3~6中可以看出,M-ISVM算法,在增量次数相同的情况下,增量的样本量无论大小,平均错分率,平均支持向量,抽样与训练总时间表现都优于X-ISVM算法,且方差更低,说明算法稳定性好。因为M-ISVM算法在马氏抽样起始转移概率的定义上利用了2→T的数据子集的分类模型,而X-ISVM算法只利用了第一次随机抽样的分类模型,在每次增量的数据上,M-ISVM算法分别从每一次数据子集中选取,而X-ISVM则在整体训练集中选取,所以M-ISVM算法能更好地兼顾全局性,很大程度上避免实验结果的偶然性。实验结果表明,M-ISVM算法的泛化性能优于X-ISVM算法。
| 图表编号 | XD0036351800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.25 |
| 作者 | 余炎、徐婕、陈前、杨艳 |
| 绘制单位 | 湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、武汉晴川学院计算机科学学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}