《表1 实验参数设置:基于深度强化学习的轨道式巡检机器人巡检驻点规划方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于深度强化学习的轨道式巡检机器人巡检驻点规划方法》
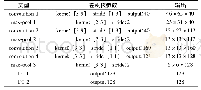
设计实验验证算法的工作情况。在Ubuntu16.04系统中基于Tensor Flow2.0框架和Gym1.0.0强化学习框架构建算法仿真环境。各项参数取值如表1所示,训练和应用的效果如图6和7所示。
| 图表编号 | XD00197058800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.15 |
| 作者 | 谷湘煜、彭志远、鲜开义、杨利萍、陈伟、邹娟、刘满禄 |
| 绘制单位 | 深圳市朗驰欣创科技股份有限公司、深圳市朗驰欣创科技股份有限公司、深圳市朗驰欣创科技股份有限公司、深圳市朗驰欣创科技股份有限公司、深圳市朗驰欣创科技股份有限公司、深圳市朗驰欣创科技股份有限公司、西南科技大学 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}