《表3 DV-CNN的分类结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
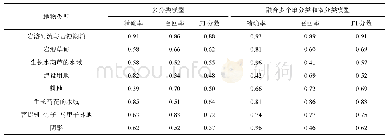
DV-CNN在Indian Pines数据集和Pavia University Scene数据集上的分类精度及标准差见表3。Indian Pines数据集上DV-CNN的OA为87.87%,AA为82.88%,Kappa系数为0.862;Pavia University Scene数据集上DV-CNN的OA为98.18%,AA为97.20%,Kappa系数为0.976。Pavia University Scene数据集的分类结果优于Indian Pines数据集,其中一个主要因素是数据量。在Indian Pines数据集中,在145×145区域中有10 249个标记的像素,但在Pavia University Scene数据集中,在610×340区域中有42 776个标记的像素。在深度学习模型中,数据量的大小往往是影响训练效果的关键因素。DV-CNN在Indian Pines数据集和Pavia University Scene数据集上的分类结果如图12所示。
| 图表编号 | XD0098408600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.16 |
| 作者 | 刘万军、尹岫、曲海成、刘腊梅 |
| 绘制单位 | 辽宁工程技术大学软件学院、辽宁工程技术大学软件学院、辽宁工程技术大学软件学院、辽宁工程技术大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}