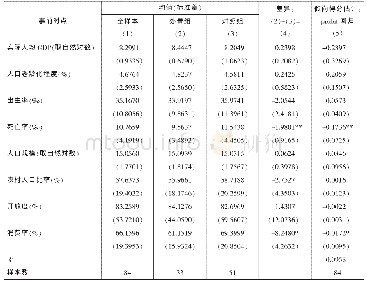
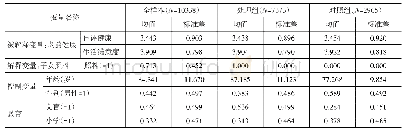
《表3 匹配变量的描述性统计和倾向得分估计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:为确保描述性统计和倾向得分估计的样本量是一致的,从而具有良好的可比性,本文在描述性统计中剔除了匹配变量缺失的样本。第(4)和(5)列小括号里的数字为标准误。倾向得分估计模型的回归结果略去了截距项的回归系数。*、**和***分别表示在10%、5%和1%的置信水平上显著。
这些变量采用的都是1981—1985年(即事前时点)的均值。这样的处理不仅可以确保它们不受社会保障制度建立及其预期效应的影响,也可以避免短期波动的影响。对于这些变量,本文剔除了小于1%分位数和大于99%分位数的观测值以避免异常值的影响。由表3可知:匹配前,相较于对照组而言,处置组在事前时点具有较低的死亡率和消费率,表明社会保障制度的建立并非随机的,需要校正选择偏差问题。
| 图表编号 | XD0020301200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.11.17 |
| 作者 | 贾俊雪、李紫霄、秦聪 |
| 绘制单位 | 中国人民大学国家发展与战略研究院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}