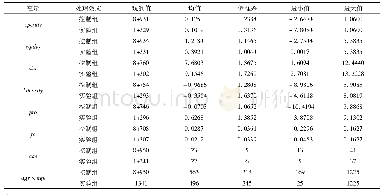
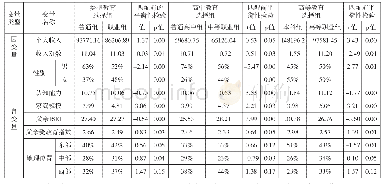
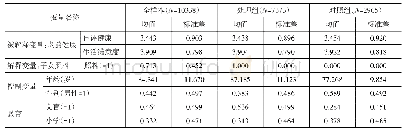
《表2 倾向得分匹配 (PSM) 匹配特征变量描述性统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《国有企业的海外并购是否创造了价值:基于PSM和DID方法的实证检验》
资料来源:笔者利用stata 15.0软件计算。表3、表4、表5、表6和表7注同。
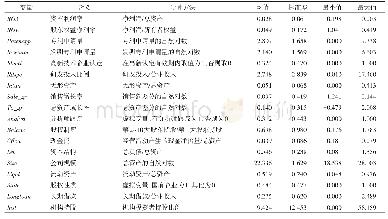
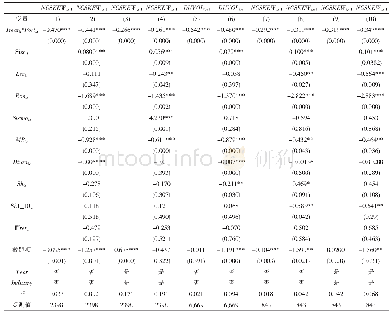
本文主要采用最近邻匹配法(nearest neighbor matching)进行匹配,参与匹配的实验组与控制组样本分布及描述性统计如表2、表3所示。匹配细节如下:(1)当出现距实验组距离一样的两个控制组样本时,允许并列(ties),以便提高匹配的效率。(2)本文的观测区间为2007~2015年,由于实验组受到政策的冲击时点并不一致,因此,存在对实验组样本进行逐年匹配的必要性(杨德彬,2016;薛安伟,2017;蒋冠宏,2017)。匹配的目的在于“按图索骥”,即为实验组寻找与其特征变量最为相似的控制组样本。由于参与匹配的特征变量不止一个,匹配问题由“一维”陡增到“多维”以完成匹配过程。
| 图表编号 | XD0052970100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.25 |
| 作者 | 吴先明、张玉梅 |
| 绘制单位 | 武汉大学经济与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}